Fine-tuning open models in the real world: Unsloth, Axolotl, and the case for Docker

If you’re a human reading this, here’s the TL;DR:
Fine-tuning frameworks weren’t the hard part. The environment was.
If you are training GPU models in production:
- Pick whatever framework fits your workflow.
- Run it inside Docker.
- Pin the image tag.
- Treat the environment as part of your codebase.
The difference between “it works” and “it reliably works” is the boundary around your dependencies.
For us, that boundary was Docker.
Background
We have been building a Machine Learning based pipeline at Curlscape that fine-tunes small language models to spot PII/PCI like passwords, API keys etc in text. Over the course of the project we experimented with several open generative models, including Gemma variants, TinyLlama, and architectures from the LLaMA and Mistral families. The model choice kept shifting as we learned more about what worked for our data and what did not. But the model was never really the hard part. The tooling and environment around fine-tuning were where the real friction lived. This post focuses on the tooling and infrastructure around fine-tuning: what broke, what worked, and why we ultimately wrapped everything in Docker to stay sane. We’ll talk about model performance and comparative results in a separate article.
That context matters, because the hardest lessons we learned had very little to do with the models themselves.
If you have ever tried to fine-tune an open language model, you probably know the feeling. You find a promising framework, install it, point it at your data, and hit run. Then you spend the next several hours debugging why PyTorch cannot see the GPU. We worked with three different training approaches during the project: Unsloth, standard Hugging Face with PEFT, and Axolotl. We spent more time fighting dependency issues than evaluating either framework. Which tool you pick matters less than whether your environment is reproducible. This post is about what that journey was actually like, and why Docker turned out to matter more than any of them.
Our Approach
Context
By the time we started experimenting with fine-tuning, most of our infrastructure was already containerized and running inside Docker. The backend was stable and isolated.
While working with this customer, we had built a synthetic data generation pipeline that produced data in a format specific to their use case. On top of that, we developed a data wrangling layer that could take both synthetic and existing data and transform it into the structured format required by our machine learning models.
All of this ran inside a FastAPI-based backend system.
The open question was not whether we could fine-tune a model. It was how to integrate a GPU training pipeline into an existing production backend without breaking the guarantees we already had around isolation, reproducibility, and deployment.
Model training
Our model training strategy was instruction tuning. We took pre-trained models and adapted them to a specific task format: given a block of text, identify credentials and return structured detections. The base model already knew how to generate text. Fine-tuning taught it to respond predictably and consistently for our use case. Once that was in place, we started testing the tooling, and that is where things became interesting.
Choice of fine tuning platform
We evaluated Unsloth and Axolotl side by side and planned to choose whichever integrated best with the system we had. Unsloth offered a lightweight, Python-first layer on top of Hugging Face, optimized for speed and memory efficiency. Axolotl took a different approach, describing the entire training run in YAML and executing it as a self-contained job. Along the way, we also worked directly with standard Hugging Face and PEFT, even though that was not part of the original plan.
Working with Unsloth
from unsloth import FastLanguageModel
model = FastLanguageModel.from_pretrained(...)
for batch in batches:
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()On paper, it feels like a drop-in performance upgrade.
Dependency issues
Installation is deceptively smooth. pip install unsloth succeeds without complaint. The issues start at import time. Across different machines, we saw CUDA version mismatches, Triton compilation failures, and occasional segfaults. Unsloth compiles Triton kernels against the runtime CUDA environment at import, not at install. A successful pip install does not guarantee a working runtime. You only find out when you try to train. The install step succeeded, but runtime could still fail due to a driver mismatch.
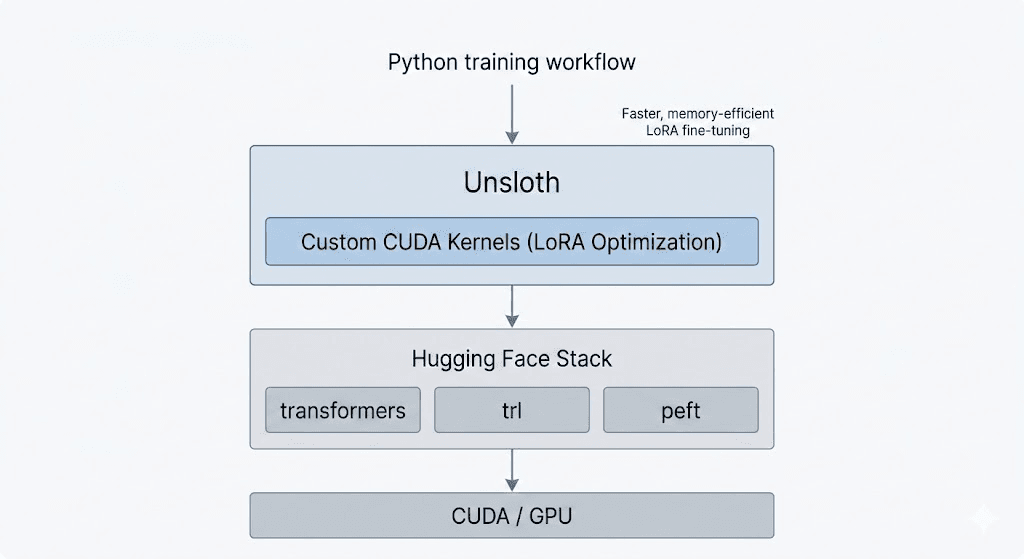
Unsloth's training workflow
We also ran into transitive conflicts. Unsloth pulled in specific versions of triton, xformers, and bitsandbytes that sometimes clashed with our transformers and trl versions. In one case, trl was silently downgraded, breaking SFTTrainer at runtime.
When Unsloth worked, it was fast and memory-efficient. The problem was not capability. It was predictability. For production training, that gap mattered more than raw speed.
The Hugging Face + PEFT Setup
After working through higher-level abstractions, we stepped back to the standard Hugging Face stack with PEFT.
This path removed extra layers and forced us to interact directly with the core primitives: AutoModelForCausalLM, LoraConfig, get_peft_model, and the base Trainer. No custom kernels. No declarative training layer. Just the ecosystem in its most explicit form.
Training in this setup required more deliberate effort to achieve memory efficiency. But it was predictable. Imports did not segfault. APIs were stable. Every component was widely used and well-documented.
More importantly, this setup made the moving parts visible. Tokenization, dataset formatting, LoRA configuration, collators, masking logic all of it was explicit. Nothing was abstracted away.
It also exposed a subtle inefficiency. In the default causal language modeling setup using Hugging Face’s base Trainer and standard collator (mlm=False), loss is computed over all non-masked tokens in the sequence. In an instruction-tuning context, this means the prompt portion contributes to the loss unless those tokens are explicitly masked. As a result, part of the training signal is spent reinforcing the instruction text rather than focusing solely on the model’s response. Higher-level utilities such as TRL’s SFTTrainer handle this masking automatically, but implementing it manually makes the tradeoff visible.
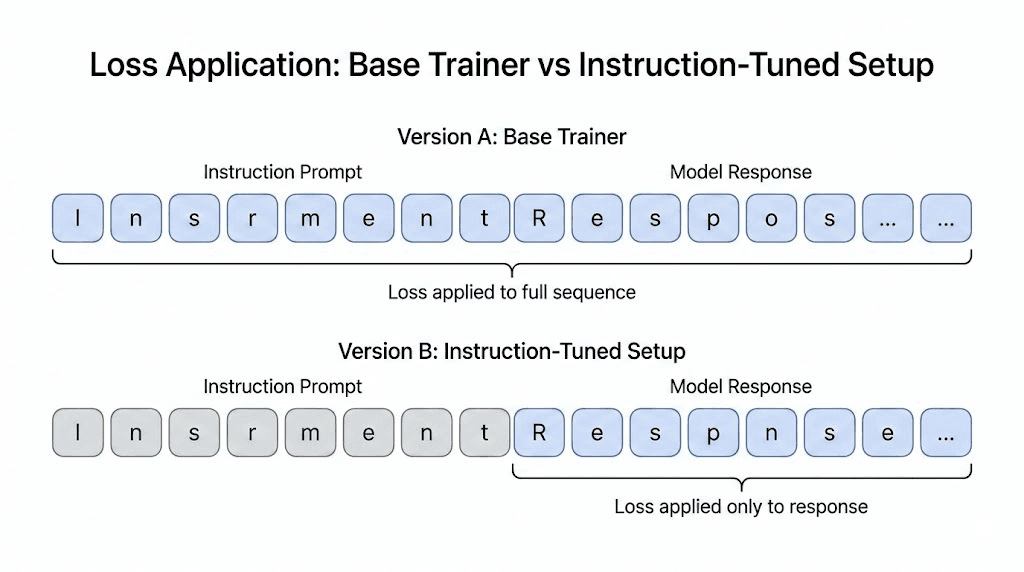
Pictorial description of loss application in both cases:
Even in this conservative setup, environment issues still surfaced when adding quantization, flash attention, or other CUDA-dependent optimizations. The Hugging Face + PEFT stack was more stable at the Python layer, but it still relied on the same GPU foundations.
This was the clearest version of the ecosystem: fewer abstractions, more control, and full visibility into the training loop. It grounded the rest of our experimentation.
Switching to Axolotl
Axolotl removed the training script entirely. A single YAML file defined the model, adapters, dataset format, masking behavior, quantization, optimization, and runtime settings. Rather than manually wiring components together, the framework orchestrated them as one cohesive training job.
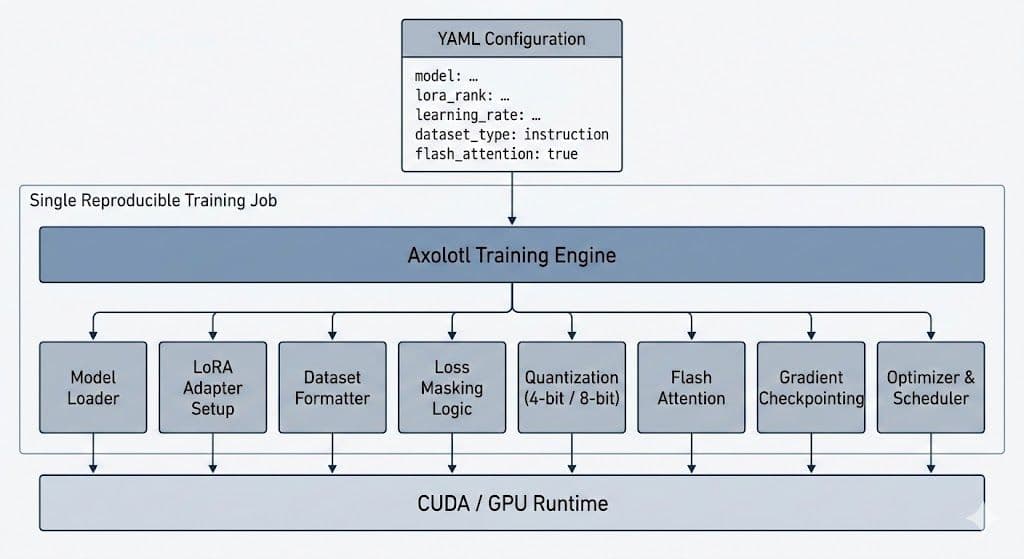
Dataflow in Axolotl
Where Axolotl surprised us
Axolotl reduced integration work, but it still requires deliberate configuration.
Watch out for how dataset paths are specified. A local JSONL path that appears correct can be interpreted differently depending on how it is declared, so it is important to verify how datasets are resolved and loaded.
While Axolotl supports evaluation workflows, integrating it into our production pipeline required additional inference and metric logic. After training completed and adapters were saved, we still handled adapter loading, tokenizer configuration, prompt formatting, output parsing, and evaluation in a way that matched our detection system. The training abstraction does not automatically become a production prediction pipeline.
Tokenizer and model configuration must also stay aligned. Adding special tokens during training triggers embedding resizing, and that change must be mirrored during inference. If not, adapter loading can fail due to dimension mismatches. This is expected behavior, but it requires consistency across training and inference.
Finally, distributed training assumptions may vary by architecture and hardware. In some configurations, we chose single-GPU runs for stability. These were operational tradeoffs, not structural issues.
All of these were configuration-level considerations. Once configured correctly, the system behaved predictably.
The real problem was the environment
After experimenting with three different training approaches, a pattern became clear. The friction was not tied to any specific framework. It lived in how the full stack had to come together.
Modern LLM training sits at the intersection of fast-moving Python libraries and a highly specialized GPU runtime. Libraries like transformers, trl, peft, bitsandbytes, and flash-attn evolve quickly. Underneath them sit CUDA drivers, toolkits, compilers, and GPU architectures that evolve more slowly and have stricter compatibility boundaries.
For training to work reliably, every layer must align.
Minor API changes in the Hugging Face ecosystem required corresponding updates in dependent libraries. Quantization libraries such as bitsandbytes depend on CUDA-specific builds that must match the host runtime. Flash Attention compiles C++ and CUDA extensions that rely on compatible toolchains. Even a conservative transformers + PEFT setup depends on version alignment across components.
None of this reflects poor library quality. It reflects the reality of high-performance GPU software: the system spans multiple layers, each with its own release cadence and constraints.
A requirements.txt file can pin Python packages. It cannot pin CUDA drivers, system compilers, or GPU architecture. The most important dependencies sit outside pip’s control.
Over time, we realized the challenge was not instability. It was coordination. The training stack is only as stable as the alignment across its layers.
And alignment at this level is not accidental. It must be enforced.
Docker as the Actual Solution
After trying multiple frameworks, the pattern was obvious. The instability wasn’t in the training code. It was in the environment. The fix was to freeze the environment.
We moved the entire training stack into Docker: Not for deployment, but for reproducibility.
Axolotl’s official image bundled everything together:
- PyTorch
- CUDA toolkit
- flash-attn
- bitsandbytes
- transformers / trl / peft
- All compiled extensions
Pre-built. Version-aligned. Tested together.
The setup became:
- Pull image (~15GB)
- Mount project
- Run training
No installation. No version matrix. No CUDA mismatch guessing.
What Changed
With pip installs, you assemble a GPU stack from independently versioned parts and hope they agree.
With Docker:
- Full dependency tree frozen
- CUDA bundled and matched
- Same behavior across machines
- Rollback via image tag
Verification moved upstream. It happened once when the image was not on every laptop.
What We Gained
Predictability.
- A run that worked once would work again.
- New machines worked immediately.
- Debugging shifted from environment drift to model behavior.
The image was 15GB. It was also 15GB of problems we no longer had to solve.
When to use which
- Unsloth is great when you want maximum speed and minimum memory usage and you’re working in a stable environment. If your setup doesn’t move between machines often, it’s a strong choice for custom or performance-sensitive training.
- Hugging Face + PEFT is the reliable baseline. It’s explicit, well-documented, and predictable. If you want full visibility into what’s happening, or if you’re learning the stack, this is a solid place to start.
- Axolotl works well for config-driven workflows and rapid iteration on hyperparameters. The declarative YAML approach reduces the amount of Python code you maintain, and the Docker image provides a tested, frozen environment out of the box.
Whichever framework you choose, use Docker.
- Run training inside a container.
- Pin your image tags.
- Cache model downloads.
- Test configs on small runs first.
- Prefer bfloat16 if your hardware supports it.
Docker does not eliminate the complexity of GPU training stacks, but it lets you solve that complexity once instead of repeatedly.
Happy training!
Need help building AI into your product?
We design, build, and integrate production AI systems. Talk directly with the engineers who'll build your solution.
Get in touch
Written by
Samudyata Minasandra
Samudyata is a generative AI intern at Curlscape focused on machine learning and artificial intelligence, with a strong grounding in mathematics. Particularly interested in the mathematical foundations of learning algorithms:
Linear algebra, probability, optimization, and graph-based methods, and in applying them to build reliable, interpretable, and scalable systems.
Frequently Asked Questions
What does Curlscape do?▼
Curlscape is an engineering-driven AI studio that helps companies design, build, and operate production AI systems. The team works with businesses to integrate artificial intelligence into real workflows, from early experimentation to full-scale deployment.
What types of AI solutions does Curlscape build?▼
Curlscape builds a range of AI systems including conversational voice agents, document intelligence tools, data enrichment pipelines, AI assistants, computer vision systems, and private AI infrastructure for companies that need to keep data on their own servers.
Who can benefit from Curlscape’s approach to reproducible AI training?▼
Companies building machine learning systems that rely on GPU training can benefit from Curlscape’s approach. Teams working with LLM fine-tuning, model training pipelines, or AI infrastructure often face environment instability, which Curlscape addresses through containerized and reproducible training setups.
How can startups benefit from Curlscape’s AI infrastructure expertise?▼
Startups building AI products often need to move quickly while maintaining reliable infrastructure. Curlscape helps startups design stable machine learning pipelines, integrate fine-tuning workflows, and deploy AI systems without spending months debugging environment issues.
Can I use CurlScape's approach with my own data and models?▼
Yes. Curlscape's platform is designed to ingest text from 200+ file types, compute entropy and pattern metrics, and prepare labeled datasets for training. You can bring your own data, label it through the platform, and fine-tune any supported open model on your specific credential patterns. The Docker-based training pipeline described in this post is how Curlscape runs training in production, and the same workflow (YAML config, containerized environment, mounted data volumes ) works for custom detection use cases. Visit curlscape.com to get started.
What is the biggest challenge when fine-tuning open language models in production?▼
The primary challenge is not model performance but environment stability. GPU training depends on tight alignment between Python libraries, CUDA drivers, toolkits, compilers, and hardware. Small version mismatches can cause runtime failures or instability, even when the training code is correct.
Why is Docker important for GPU model training?▼
Docker allows you to freeze the entire training environment, including CUDA toolkits and compiled dependencies. This ensures that a training run that works once will behave consistently across machines and over time, improving reproducibility in production ML workflows.
Is Hugging Face sufficient for production fine-tuning?▼
Yes, the standard Hugging Face stack with PEFT is stable and well-documented. However, production reliability depends on managing the surrounding GPU environment, not just the training framework itself.
When should you use Axolotl for fine-tuning?▼
Axolotl is well-suited for configuration-driven workflows and rapid experimentation. Its declarative YAML approach simplifies training orchestration, especially when combined with containerized environments.
What causes GPU training failures in practice?▼
Common causes include CUDA version mismatches, incompatible compiled extensions (such as bitsandbytes or flash-attn), and misaligned library versions. These issues often appear as runtime or segmentation errors rather than clear configuration warnings.
How can you make fine-tuning reproducible across machines?▼
Use containerization (e.g., Docker), pin image versions, cache model artifacts, and treat the training environment as part of your codebase. Reproducibility requires controlling dependencies beyond Python packages.
How can companies reduce the complexity of AI infrastructure?▼
Companies can reduce AI infrastructure complexity by standardizing environments, containerizing training pipelines, and using stable tooling. Curlscape helps teams implement these practices so machine learning workflows remain reliable as they scale.
Continue Reading

Google Gemini API Pricing Guide 2026: Flash, Pro, and Vertex AI
Current Google Gemini API pricing for 2026: Gemini 3 generation (3.1 Pro, 3.5 Flash, 3.1 Flash-Lite), what changed since 2.5, image generation with Nano Banana, and how Vertex AI costs compare.

Anthropic Claude API Pricing Guide 2026: Opus, Sonnet, and Haiku Compared
Complete Anthropic Claude API pricing for March 2026. Compare Opus, Sonnet 4.6, and Haiku 4.5 with batch discounts, prompt caching savings, rate limits, and real-world cost breakdowns.

OpenAI API Pricing Guide 2026: Every Model Compared
Every OpenAI API model priced and compared for 2026, from GPT-5.2 to o4 Mini. Includes real-world cost calculations for chatbots, pipelines, and more.